On April 7, 2026, a model with no readme, no team page, and zero launch hype appeared on the Artificial Analysis Video Arena — and immediately hit #1 in both text-to-video and image-to-video. Nobody knew who built it. Three days later, CNBC broke the story: Alibaba. The real kicker? The engineer who led it is the same person who built Kling AI — the model HappyHorse just dethroned.

The Story
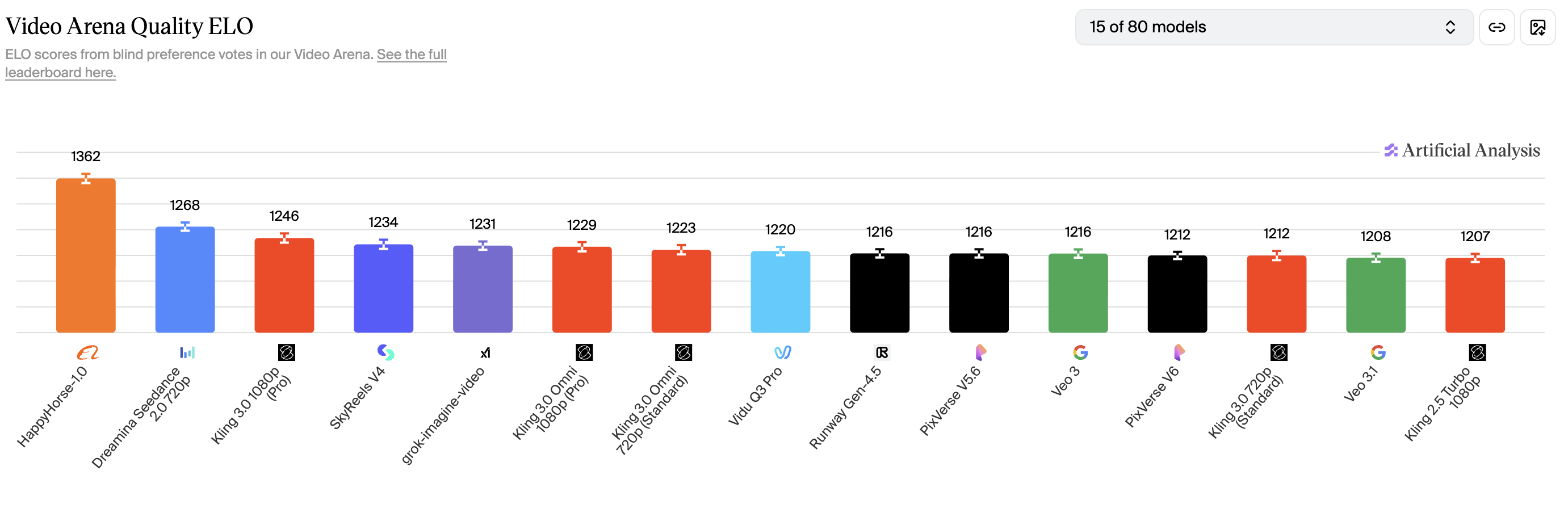
The Artificial Analysis Video Arena is a blind-voting leaderboard: users compare two AI-generated videos side by side without knowing which model produced which. Every vote feeds into an Elo rating system — no vendor cherry-picking, no self-reported benchmarks. It’s the closest thing to ground truth the AI video space has.
When HappyHorse-1.0 appeared there in early April, it didn’t just edge out the competition. It absolutely stomped:
- Text-to-Video (no audio): Elo 1,366 — #1, over 100 points ahead of Seedance 2.0
- Image-to-Video (no audio): Elo 1,413 — #1, a new all-time record on the platform
- Audio-inclusive tracks: Solid #2, neck-and-neck with ByteDance
The community immediately started speculating. The outputs had tell-tale signs of a Chinese research team. The architecture felt like an evolution of Wan 2.7. Then on April 10, CNBC confirmed it: HappyHorse-1.0 was built by Alibaba’s ATH AI Innovation Unit, formerly the Taotian Group Future Life Laboratory.
But here’s the plot twist that makes this a genuine IK3D story: the team is led by Zhang Di, former Vice President at Kuaishou and the technical architect of Kling AI. The person who designed Kling — which our blog literally just crowned the AI Video King on April 20 — left to build something that dethrones it. That’s a cinematic arc if we’ve ever seen one.
What Makes It Different
Most AI video generators have the same fundamental limitation: they generate silent video. Audio is bolted on after — either with a separate TTS model, manually in post, or not at all. HappyHorse-1.0 throws that pipeline in the trash.
Under the hood it runs a 15-billion-parameter single-stream Transformer with 40 layers. Text tokens, image tokens, video frames, and audio tokens all travel through the same attention mechanism in a single forward pass. The model doesn’t “add” audio — it generates both simultaneously, the way you’d shoot a scene on a real set with a live microphone.
That unified architecture delivers some capabilities that matter a lot to the IK3D audience:
- Native 7-language lip-sync: Mandarin, Cantonese, English, Japanese, Korean, German, French — phoneme-level synchronization baked in, not fine-tuned after the fact
- 1080p in 38 seconds on a single H100: not a cluster of GPUs, one card
- 8-step denoising: no CFG (classifier-free guidance) required, which is part of why it’s fast
- True multi-shot generation: scene cuts, camera changes, spatial continuity across a sequence — not just one static camera angle per clip
Reviewers consistently flag two standout areas: skin texture and motion. The model has an unusual fidelity for facial detail and the movement physics feel grounded — no more randomly floating hands or teleporting subjects.
Why You Should Care
Two words: open source. HappyHorse-1.0 ships with Apache 2.0 licensing — full commercial rights, no royalties, no platform lock-in. Weights are on HuggingFace, code is on GitHub, distilled versions are included for people who don’t have H100s, and a super-resolution module is part of the package.
For creative technologists, that changes the math entirely. You can:
- Run it locally for client work without subscription costs
- Fine-tune it on your own footage for a consistent visual style
- Integrate it into ComfyUI pipelines as an image-to-video node
- Build tools on top of it for clients — commercially, legally, cleanly
For 3D artists specifically, image-to-video at #1 rank is the unlock you’ve been waiting for. Render a still from your Blender or Cinema 4D scene, feed it to HappyHorse with a motion prompt, and get an animated shot back — with ambient audio, no separate pass required. For architectural visualization, this is pre-viz generation that can go straight into a client presentation.
For game devs, the native audio generation combined with 7-language lip-sync opens up a cutscene pipeline that would have cost six figures to produce two years ago. Feed it a character sheet (image-to-video), describe the motion and emotion, get a cinematic with localized voice acting in seven languages from a single generation call.

Try It
- GitHub: CalvintheBear/HappyHorse-1.0 — full weights, distilled variants, inference code
- HuggingFace: happyhorse-ai/happyhorse-1.0 — T2V, I2V, 5B lite version
- Hosted API: launching April 30 via fal.ai/happyhorse-1.0 — no GPU required, pay per generation
- Benchmark: track rankings live at Artificial Analysis Video Arena
Local deployment needs 40GB+ VRAM (H100/A100) for the full model, or quantized/distilled versions for RTX 4090s. The API on April 30 is where most creatives will want to start.
IK3D Lab Take
The anonymous launch was a power move. Let the blind benchmarks speak. No influencer campaign, no hype cycle — just outputs and Elo points. That confidence tells you something about how the team felt about the work.
But the bigger signal here is what this moment represents: open-source video AI has officially reached and surpassed the closed-source frontier. Kling 3.0 costs $13.44/min. Veo 3.1 lives inside Google’s ecosystem. Sora 2 requires an OpenAI subscription. HappyHorse-1.0 is Apache 2.0 and runs on hardware you can rent for $2/hr.
For the IK3D community — people building real pipelines, real tools, real client work — this is the video model we’ve been waiting for. Not because it’s free (though that helps), but because you can actually own it. And when Zhang Di’s team drops HappyHorse 2.0, you’ll already have the infrastructure in place to upgrade.
The king is dead. Long live the open source.



