
Animal fur and muscle have always been the wall every CG studio hits. A believable tiger means a multi-million-strand groom, a muscle and skin solver, secondary motion on every hair, and then a render queue that eats nights for breakfast. A team out of Tsinghua just published MoZoo, a generative dynamics solver that takes a coarse, untextured mesh and hallucinates the whole thing — fur, jiggle, muscle slide and all — as finished video. It is the most upvoted creative-AI paper on Hugging Face this week, and once you see it move, you understand why.
The Story
MoZoo (the name is a wink at “motion” plus “zoo”) reframes one of VFX’s nastiest problems. Instead of simulating physics — grooming hair, caching cloth-style fur dynamics, solving muscle deformation, then path-tracing the result — it treats the whole job as a video-generation task. You feed it a rough animated mesh and a reference image of the animal you want, and a video diffusion model paints high-fidelity, temporally stable footage of that creature in motion. The coarse mesh is the choreography; the diffusion model is the entire fur-and-skin pipeline collapsed into one inference pass.
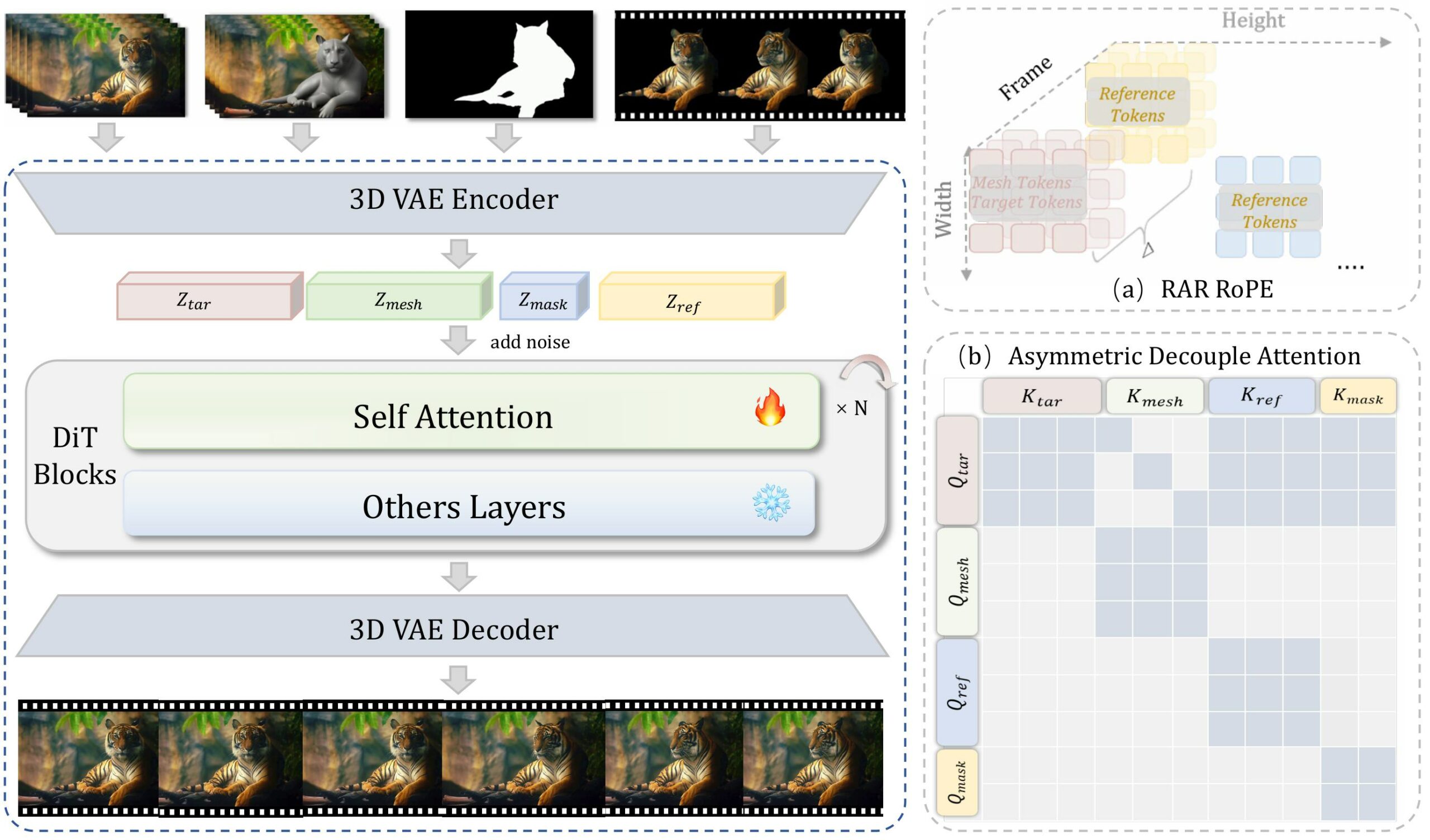
Making a video model respect both the motion from the mesh and the identity from a reference photo without the two bleeding into each other is the hard part. MoZoo’s two key tricks are Role-Aware RoPE (RAR-RoPE), which remaps positional indices by role so motion stays aligned while reference information is held at a fixed temporal offset, and Asymmetric Decoupled Attention, which partitions the latent sequence to force a one-way flow of information and stop the reference frame from corrupting the animation. In plain terms: the pose comes from your mesh, the look comes from your reference, and they don’t fight.
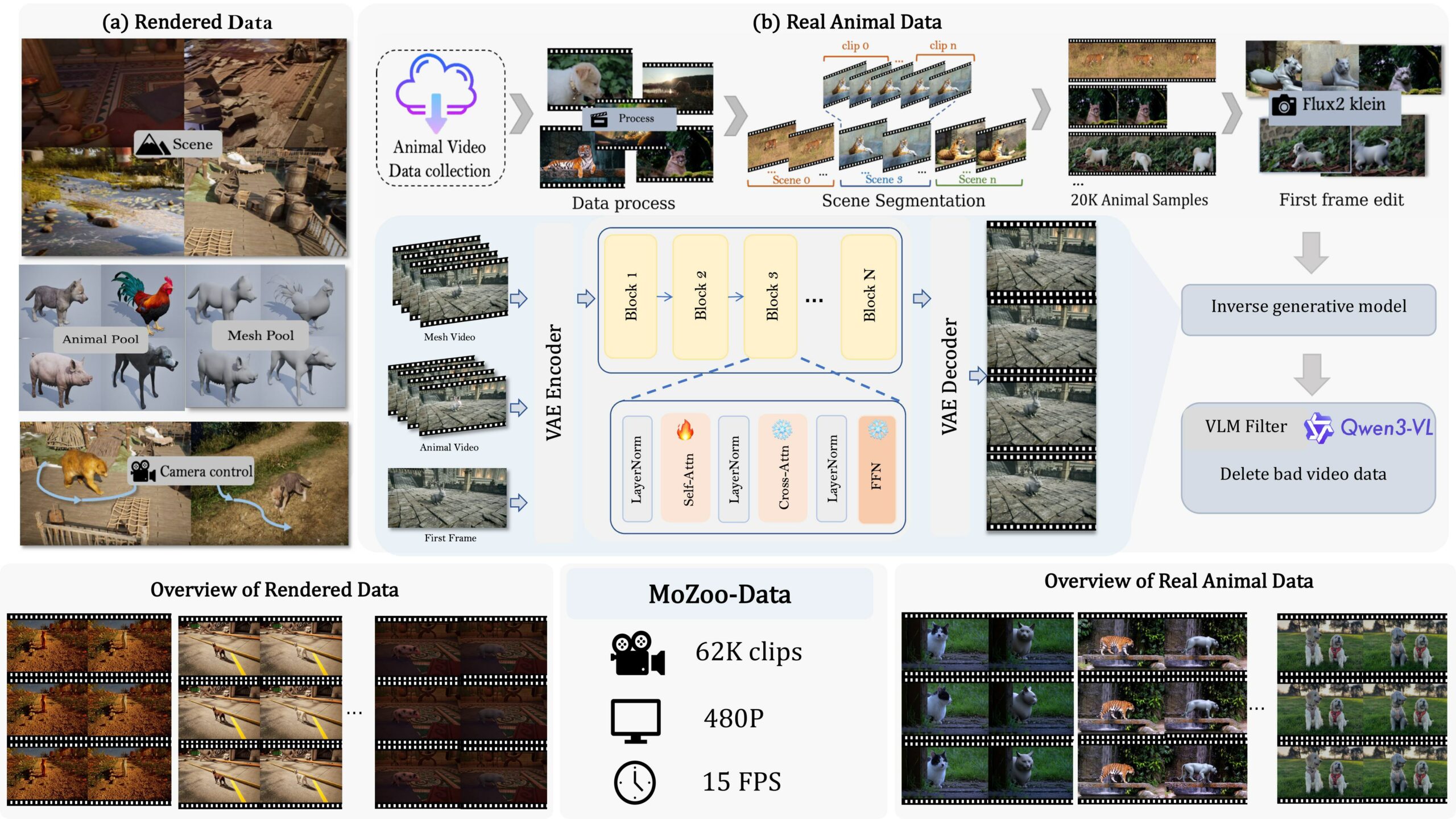
Diffusion models are only as good as their training data, and paired “coarse-mesh → cinematic-animal” sequences simply don’t exist in the wild. So the team built their own. MoZoo-Data is a synthetic-to-real pipeline: they render animals in a traditional engine, then inverse-map back to coarse proxy geometry to manufacture perfectly aligned mesh/video pairs at scale. They also ship MoZooBench, 120 mesh-video pairs across 40+ species — tigers, pandas, panthers, lions, elephants, dogs, chimps, even hamsters — so the results are measurable, not just cherry-picked GIFs.
Why You Should Care
Fur and creature work is exactly where small teams get priced out. A single hero animal can mean weeks of grooming and a render budget that only a studio can absorb. A coarse-mesh-to-finished-shot solver flips that math — you block out the animation roughly, hand it a reference, and let the model carry the photoreal load. For previs, animation tests, indie films, game cinematics and concept work, that is the difference between “we’ll fake it” and “we’ll shoot it.”
It also slots neatly into the direction the whole field is heading — AI as the renderer. Be honest about what it is, though:
- It outputs video, not geometry. You get finished pixels, not a relightable 3D fur cache. There’s no swapping the lighting rig after the fact — the look is baked into the generation.
- Coarse mesh in, so direction stays in your hands. Unlike pure text-to-video, you author the motion — the AI dresses it. That’s a big deal for anyone who needs a shot to hit specific marks.
- It’s research, not a product. This is a paper with code, not a one-click app. Expect setup, a GPU, and rough edges — but the weights and benchmark are out in the open.

Try It / Follow Them
MoZoo is open under CC BY 4.0. The project page has the side-by-side video reels — watch those first, the motion is the whole pitch. Code lives on the Orange-3DV-Team GitHub repo, and the full method, ablations and MoZooBench numbers are in the arXiv paper (Dongxia Liu et al., Tsinghua University, with collaborators at Glasgow, CUHK and HUJING Digital Media). If you run a render farm for creature work, clone it, point it at a rough mesh, and see how close a single inference gets to your usual groom-and-sim stack.
IK3D Lab Take
We’ve spent months watching AI eat the rendering half of 3D — Gaussian splats, neural renderers, diffusion upscalers. MoZoo goes after the part everyone assumed was untouchable: the physics of living things. It won’t replace a senior groom artist on a tentpole film tomorrow, and the video-only output is a real limitation. But the core idea — rough mesh as the skeleton, diffusion model as the entire fur-skin-muscle pipeline — is the kind of shortcut that quietly resets what a two-person team can ship. The render farm just got a very strange new competitor, and it works for kibble. We’ll be watching for the version that hands back geometry.
Seen a tool that deserves the Lab treatment? Send it our way.



