
The Hook
Most AI video editors paint first and think never — you ask for one change and the whole clip subtly mutates around it. ByteDance just open-sourced Bernini, a single model that does the opposite: a language brain reads your instruction, the source video, and any reference images, and works out what you actually mean before the renderer paints a single frame. The result is the thing video editing has been missing — you name what changes, and everything you didn’t name stays frozen. No flicker, no drift. And it’s Apache-2.0.
The Story
Released in pieces across early June 2026 — the renderer weights on June 1, a lightweight 1.3B variant on June 9, and the full pipeline on June 11 — Bernini is ByteDance’s bid to collapse the entire generation-and-editing zoo into one architecture. Where most pipelines bolt together a separate model for each job, Bernini exposes one interface for six tasks: text-to-image, image editing, text-to-video, video editing, reference-to-video, and reference-guided video editing, plus content insertion. Same model, same prompt box.
The trick is a two-brain design the team frames as “understand first, then act.” A multimodal language model (Qwen2.5-VL-7B) acts as a semantic planner: it ingests the full set of inputs — your text instruction, the source video, any reference frames — and predicts a target semantic embedding before any pixels are generated. Only then does a DiT-based renderer (built on Alibaba’s open Wan 2.2 backbone) run flow-matching denoising conditioned on that plan. The edit is reasoned out as an idea, then painted.
To keep the renderer from confusing your reference image with the source footage, Bernini introduces Segment-Aware 3D Rotary Positional Embedding (SA-3D RoPE) — a way of tagging every token by which input it came from. That lets the model reason across a source clip, a reference photo, and an inserted object all at once without smearing them together, which is exactly the failure mode that makes most video edits look haunted.


ByteDance ships two families. The full Bernini pairs the 7B planner with a 14B renderer. Bernini-R is the renderer alone, in 14B and a tiny 1.3B flavor fine-tuned from Wan2.1-1.3B — which the team says lands close to the 14B model on bread-and-butter jobs like style transfer, watermark or subtitle removal, and local edits, while still trailing on hard stuff like full human generation. On the team’s own video-editing arena, Bernini claims to reach the first tier alongside leading closed-source commercial models.
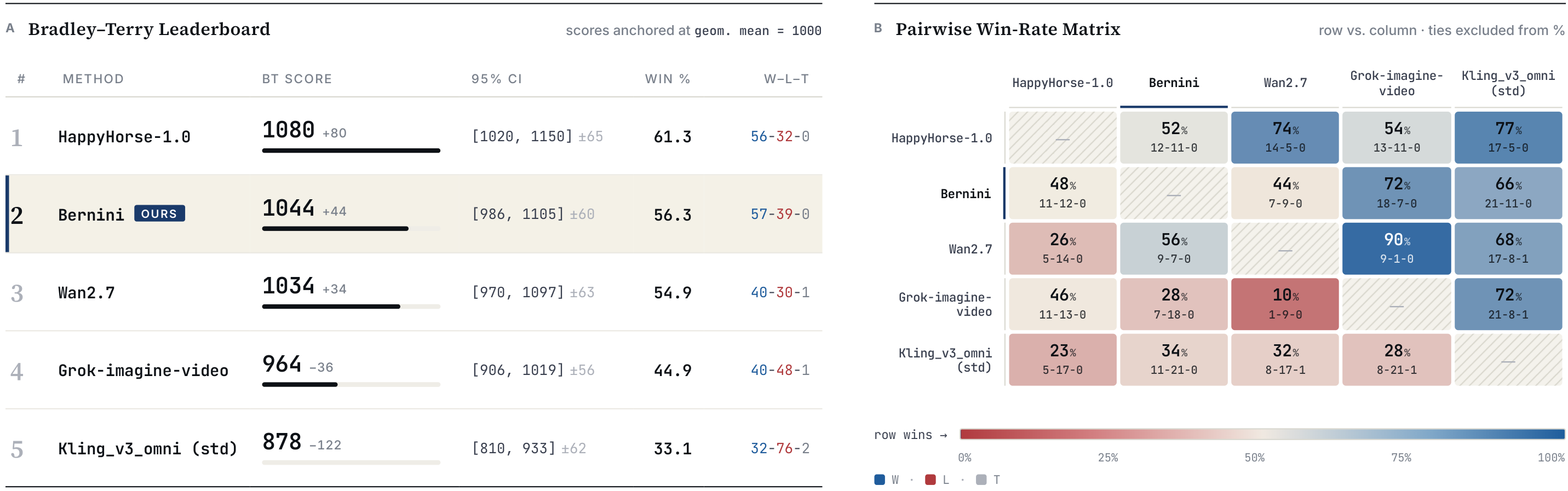
Why You Should Care
- One model replaces a pipeline. Object removal, style transfer, motion change, product insertion, text-to-video and reference-to-video used to mean stitching three or four tools together. Bernini does them from one prompt box — a real workflow simplifier for VFX, previz and motion artists.
- “Everything you don’t name stays frozen.” The planner-first design is aimed squarely at the temporal-consistency problem. Tell it what to add, remove or alter in plain language; untouched regions hold across the whole clip without the flicker and drift that plague frame-by-frame editors.
- It’s genuinely open. Apache-2.0, weights on Hugging Face, commercial use allowed. That’s the same license posture that turned Wan and FLUX into ecosystems — expect ComfyUI nodes and LoRAs fast.
- The 1.3B lowers the bar. A small renderer that performs near the 14B on common edits is the version most artists will actually run — and the one a community will build tooling around.
Try It / Follow It
Bernini is on GitHub with weights on Hugging Face (ByteDance/Bernini-R). The repo runs from clean JSON “case files” — each one bundles a task type, a plain-language prompt and its source media, so a generation is a one-liner: python infer_single_gpu.py --case assets/testcases/v2v/v2v_case1.json. That snowman-on-a-snowy-path edit in the testcases is a great first read to see how the instructions are phrased.
Reality check on hardware: this is a Hopper-class release today — the team targets H100/H800/H200 with CUDA 12.4, PyTorch 2.5.1 and FlashAttention 2/3, defaulting to 480p @ 16fps and scaling to 1280p @ 24fps. Consumer-GPU quantizations and a ComfyUI wrapper are the obvious next community step, exactly as happened with Wan and FLUX.2.
IK3D Lab Take
We keep flagging the same quiet shift across the Lab: the frontier of generative media is moving from “generate, then pray” to “reason, then generate.” We saw it in HiDream-O1 and ChatGPT Images thinking before they draw — Bernini drags that idea into video editing, the place it matters most, because that’s where a careless model wrecks the 99% of frames you wanted left alone. A semantic planner that decides the meaning of an edit before a renderer touches a pixel is, frankly, how a human editor thinks.
Is it production-ready on your laptop today? No — 480p and an H100 requirement keep it in lab-toy territory for now. But the architecture is the headline, not the resolution. An Apache-2.0, planner-plus-renderer model that unifies six tasks and protects untouched regions is a blueprint, and blueprints get optimized fast in the open-weight world. Grab the 1.3B, point it at a clip, and tell it to remove one thing. If the rest of your shot holds still, you’ll understand why we think this matters.



