Erasing a person from a video clip has been a solved-ish problem for years. Erasing the shadow they cast, the reflection they left in the window, and the stack of dominoes their hand just toppled? That has been pure fantasy — until Netflix open-sourced VOID. It is the streaming giant’s first public AI model, it ships under Apache 2.0, and as of 14 May it runs natively inside ComfyUI.
The Story
VOID — Video Object and Interaction Deletion — comes out of a collaboration between Netflix’s AI team and INSAIT in Sofia, led by Saman Motamed. The paper dropped on arXiv in early April; the weights went up on Hugging Face the same week; and a month later the ComfyUI team wired in native support alongside Google’s Gemma 4 and BiRefNet.
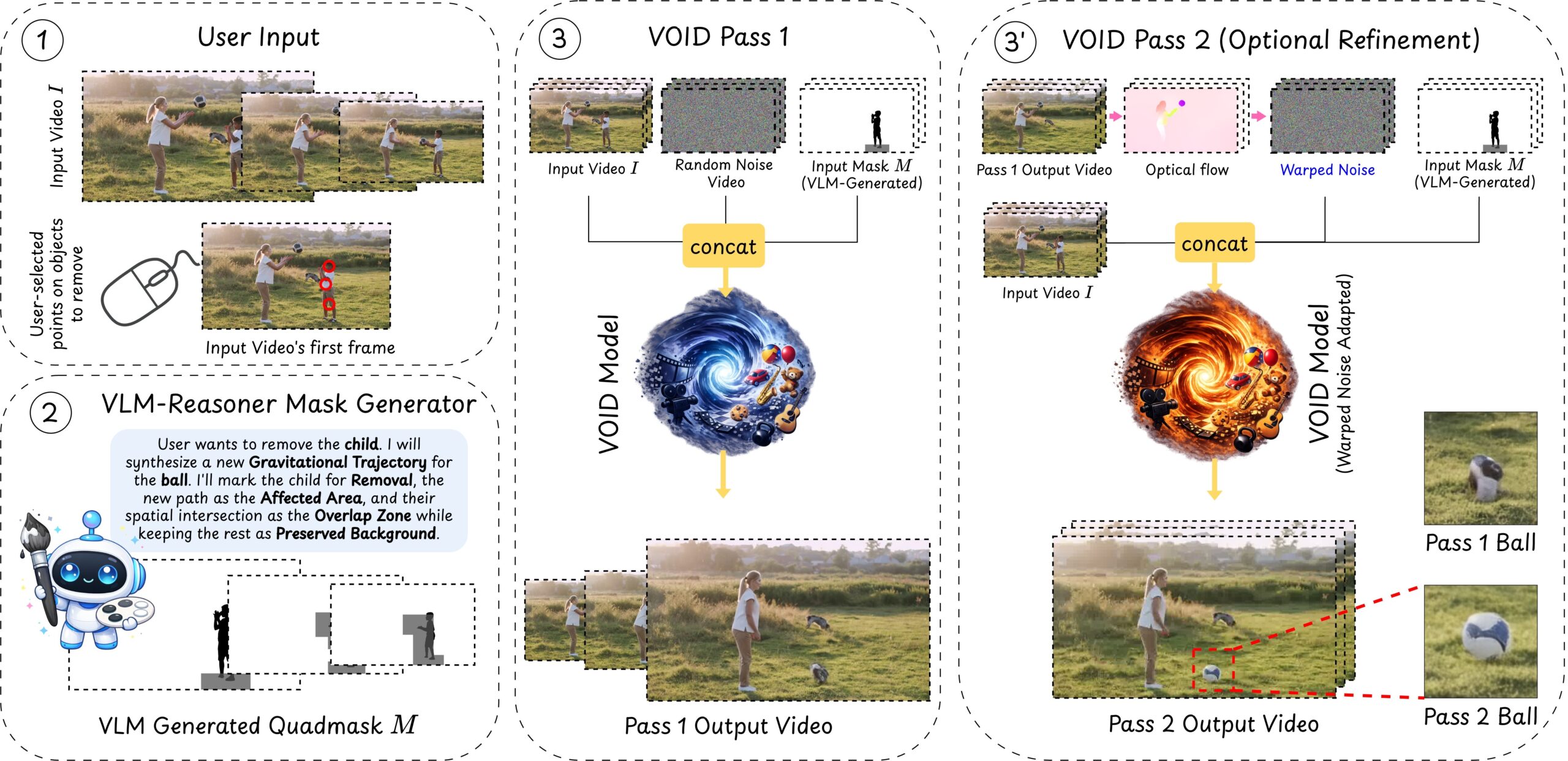
The clever bit is the input. Most inpainting models take a binary mask: white means “paint over this,” black means “leave it alone.” VOID takes a quadmask — a grayscale map with four values. 0 marks the object to delete, 63 marks overlap regions, 127 marks zones that will be physically affected by the removal (the dominoes that should now stay standing, the water that should never have splashed), and 255 marks the background to protect. That single design choice turns inpainting from a pixel-filling task into a cause-and-effect reasoning task.

Under the hood it is a fine-tune of Alibaba’s CogVideoX-Fun-V1.5-5b-InP, a 5-billion-parameter 3D-transformer video model. Netflix trained it on two synthetic, physics-accurate datasets: HUMOTO (motion-capture human-object interactions re-simulated and rendered in Blender) and Google’s Kubric (object-collision scenes with ground-truth “counterfactual” videos showing what the scene looks like with an object never present). Because the training pairs are synthetic, the model gets a perfect before/after for every interaction — something you could never capture by hand.
There is a two-pass architecture, too. Pass 1 does the base removal. Pass 2 is optional and fixes “object morphing” — the warping artifacts that creep in over long clips — by re-initializing from optical-flow-warped latents of Pass 1. In a user study the team ran VOID against ProPainter, DiffuEraser, MiniMax-Remover, ROSE, Gen-Omnimatte and Runway, and it came out on top for temporal consistency.

Why You Should Care
If you do VFX, cleanup, or any kind of plate prep, this is the model that finally understands that the world reacts to the thing you are deleting. Rig removal, crew reflections in a car door, a stand-in actor casting a shadow on the hero — these are the jobs that eat roto hours, and VOID takes a real swing at all of them. It is also a quietly huge signal: Netflix shipping an open, Apache-2.0 production tool rather than locking it behind an internal pipeline is the kind of move that drags the whole industry forward.
For the ComfyUI crowd, the native integration means you can drop VOID into the same graph as your segmentation, upscaling, and color nodes — no separate environment, no glue scripts. Pair it with SAM3 to auto-generate the masks and you have a near-push-button removal workflow.

Try It / Follow Them
- Live demo (no install): the Hugging Face Space
- Weights: netflix/void-model on Hugging Face (Apache 2.0)
- Code: github.com/netflix/void-model
- ComfyUI: grab the model package and template from the Comfy-Org repos, or test it on Comfy Cloud
- Paper: VOID on arXiv · Project page: void-model.github.io
The catch: VOID wants 40 GB+ of VRAM (think A100). It runs at 384×672, up to 197 frames, BF16 with FP8 quantization. Local-first creators on a single consumer GPU will be leaning on the Hugging Face Space or Comfy Cloud for now — but the architecture is public, and quantized community builds are exactly the kind of thing that follows an open release.
IK3D Lab Take
The quadmask is the idea worth stealing here. By encoding consequence directly into the conditioning signal, Netflix sidestepped the usual approach of bolting a physics simulator onto a video model — they just taught the diffusion model what “affected region” means and let it generalize. That trick will show up far beyond object removal. For now, VOID is the most genuinely useful open video tool we have seen this month, and the 40 GB barrier is the only thing standing between it and your timeline. Watch the community quantizations — that wall comes down fast.


