Everyone’s chasing Sora and Runway. Meanwhile, Alibaba quietly shipped what may be the most capable open-source video generation stack on the planet — and the whole thing runs on your own machine.
The Story
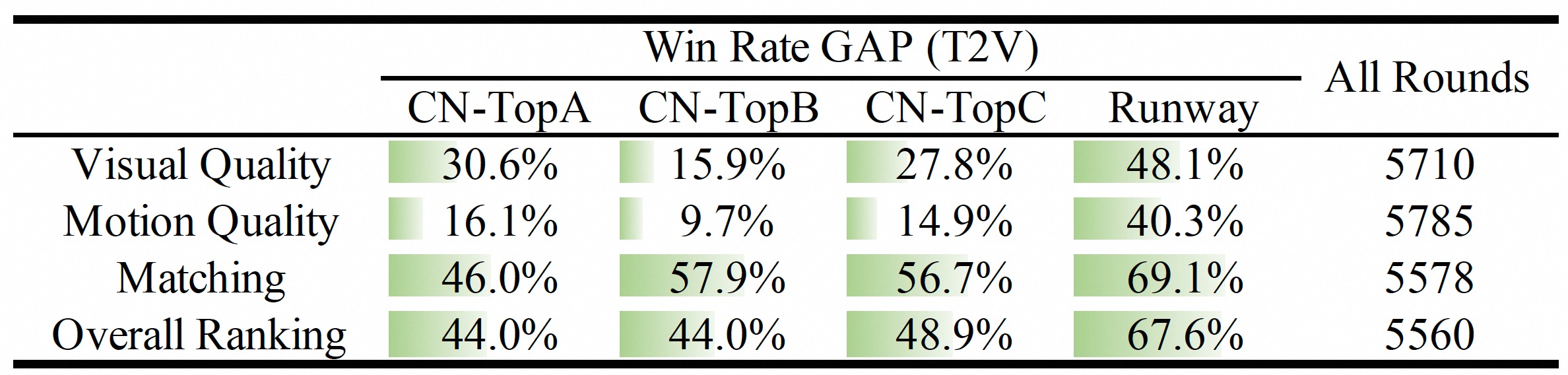
The Wan series started as Alibaba’s bet on an open-source video generation foundation. Wan2.1 landed as the top performer on the VBench leaderboard, beating out every closed competitor at the time. Then Wan2.2 followed with a Mixture-of-Experts (MoE) architecture that expanded model capacity without increasing inference cost. Now the commercial Wan platform has shipped what third-party reviewers are calling Wan 2.7 — and the feature delta is substantial enough to rewrite what “open-source video AI” means in 2026.
The headline upgrades:
- Native 4K output — up to 20-30 second clips, not just upscaled 1080p
- Instruction-based video editing — describe changes to an existing video in natural language and the model applies them. “Add fog to the background.” “Shift the lighting to golden hour.” “Pan left while racking focus.” It actually listens.
- First + Last frame control simultaneously — you define the opening and closing keyframe and the model generates the motion between them. Finally, storyboard-accurate AI video.
- Multi-reference inputs — feed up to 5 video clips as context. The 9-grid layout lets you compose more complex scenes with richer spatial references.
- Subject + voice reference combined — character consistency AND voice matching in a single generation pass, no post-production lip sync needed.
The architecture behind all this is worth understanding. Wan’s Diffusion Transformer (DiT) uses Full Attention — meaning it evaluates spatial and temporal relationships across the entire video sequence simultaneously, not frame-by-frame. This is why motion stays coherent over long sequences where other models drift. Add MoE routing (specialists per denoising timestep) and you get expanding model intelligence without proportional compute costs.
Why You Should Care
If you’re a 3D artist or VFX person, Wan 2.7 just became your pre-visualization engine. Concept animation used to require either expensive tools or a lot of manual keyframe work. Now you describe the motion, set start and end frames, and iterate. The instruction-based editing loop alone kills what used to be a half-day round of revisions.
If you’re a game developer, the cinematic pipeline just got a serious shortcut. Early in production, when you need to pitch a mood or animate a prototype cutscene, Wan 2.7 can generate placeholder cinematics fast enough to survive sprint reviews — and the first/last frame control means you can actually hit your scripted beats.
If you’re an AI art creator, the open-source model suite (six variants, from a 1.3B that runs on 8GB VRAM to the full 14B at 80GB) means you’re not locked into an API. No rate limits. No per-frame pricing. No content policy that refuses to render your creature concept. The creative pipeline is yours.
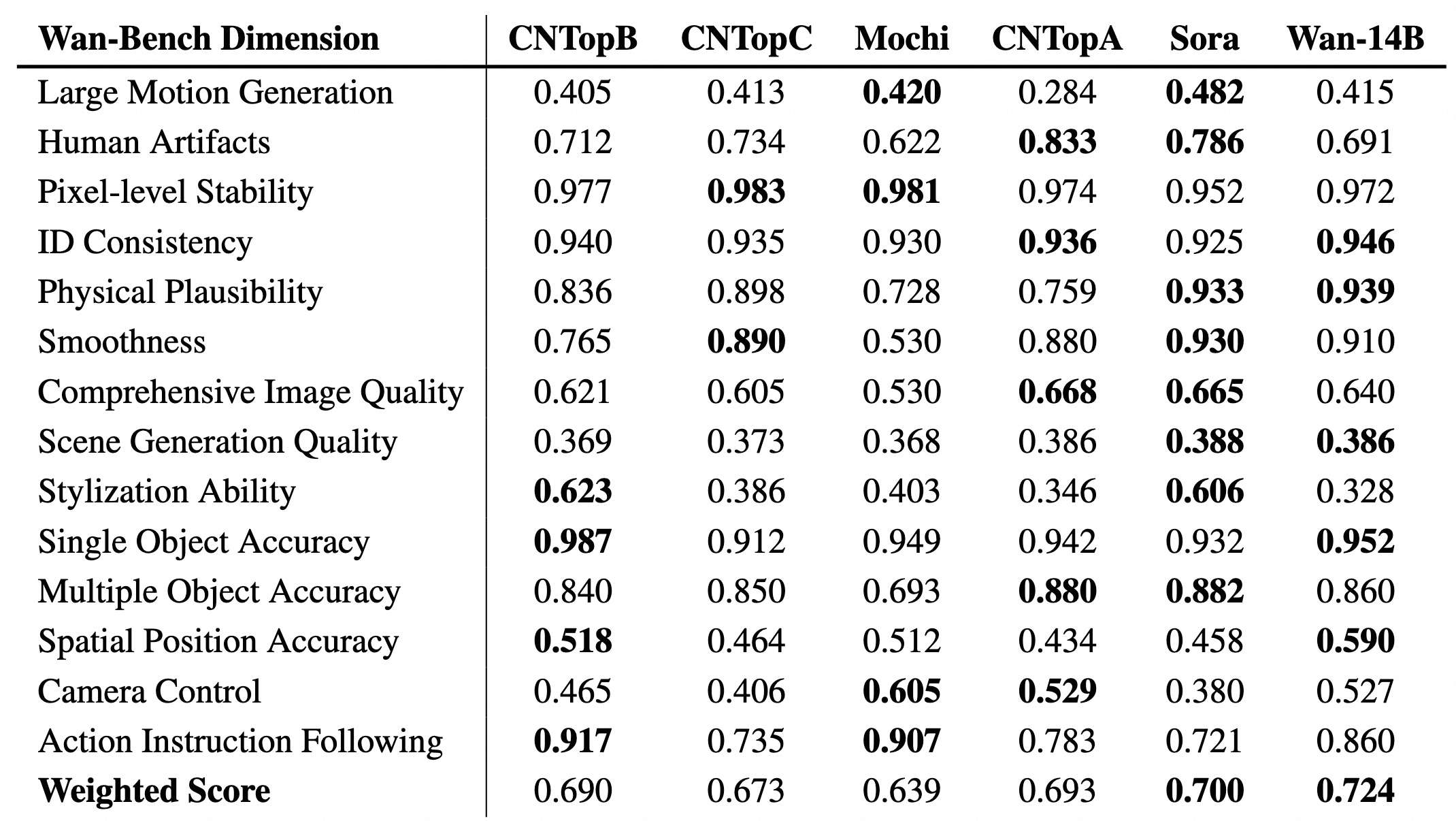
And the benchmark numbers back up the hype — Wan2.1 already held the top spot across 26 evaluation dimensions in VBench before 2.7’s improvements landed:
Try It / Follow It
Run it locally:
- GitHub (Wan2.1 — battle-tested): github.com/Wan-Video/Wan2.1 — full install docs, ComfyUI nodes, and model download scripts
- GitHub (Wan2.2 — latest architecture): github.com/Wan-Video/Wan2.2
- HuggingFace (all model weights): huggingface.co/Wan-AI — T2V-1.3B for consumer GPUs (8GB VRAM), TI2V-5B for mid-range (24GB), T2V-14B for workstation setups
Try it in the cloud first (no setup):
- WaveSpeedAI — fast inference API, Wan 2.7 features available
- SeaArt — browser-based, ~$0.40-0.60 per 5-second clip for testing
The full model lineup (for reference when picking what to deploy):
| Model | Task | VRAM |
|---|---|---|
| T2V-1.3B | Text-to-Video | 8 GB |
| TI2V-5B | Text+Image-to-Video | 24 GB |
| FLF2V-14B | First+Last Frame to Video | 40+ GB |
| T2V-14B | Text-to-Video (full quality) | 80 GB |
| Animate-14B | Character Animation | 80 GB |
IK3D Lab Take
The gap between proprietary and open-source video AI is closing faster than anyone expected. Six months ago, Sora and Runway owned a quality moat that felt insurmountable. Wan 2.7 hasn’t fully closed that gap in every dimension — the 14B model needs serious hardware, and the commercial platform wrapping 2.7’s best features isn’t fully transparent yet. But the trajectory is unmistakable.
What stands out from a creative pipeline perspective is the combination of instruction-based editing + first/last frame control. That’s not just better generation — that’s a fundamentally different relationship with the tool. You stop begging the model to give you something useful and start directing it. For 3D artists who’ve been frustrated by AI tools that produce pretty noise they can’t control, this is the shift that changes the daily workflow.
The Wan2.2 MoE architecture also signals where this is heading architecturally: specialized sub-models for different denoising stages, more intelligence at the same compute cost. That’s a scaling path that can keep compounding. Watch this project closely — the 2.2 million downloads on Wan2.1 alone tell you the community is already running with it.
Wan2.1 and Wan2.2 are released under Apache 2.0. Open for commercial use. No strings.